Graphics
R Foundations Course
December 5, 2023
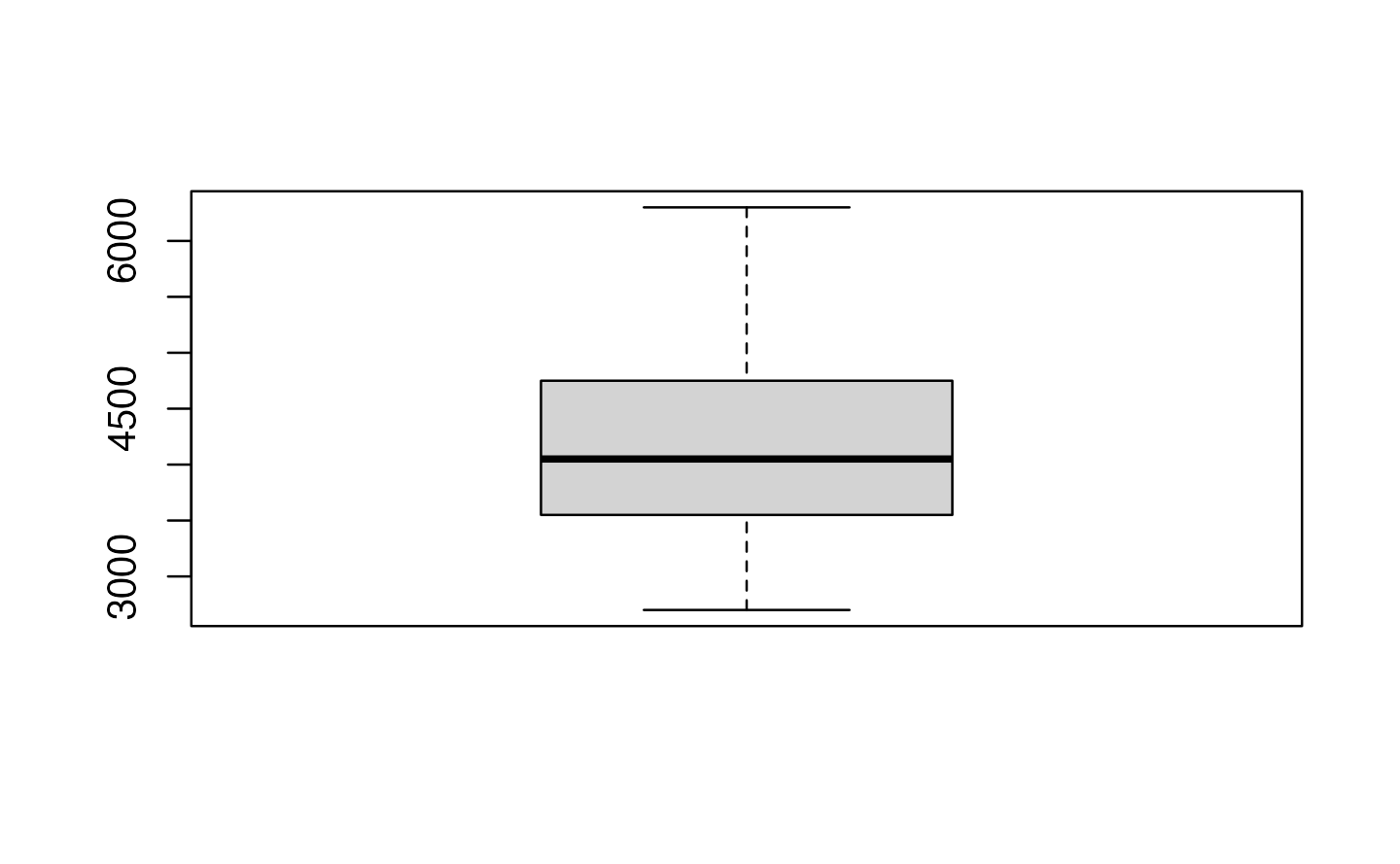
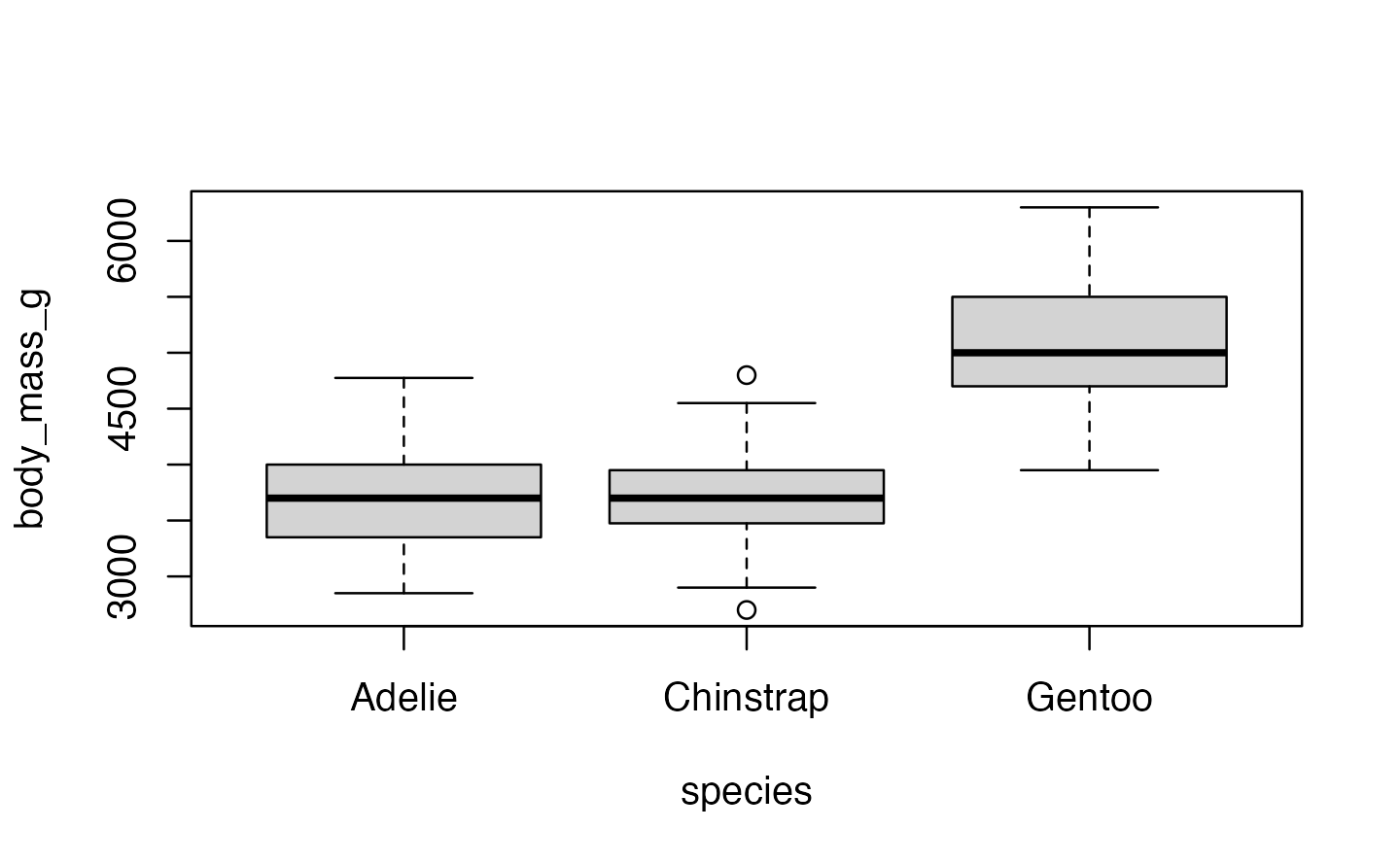
Boxplots
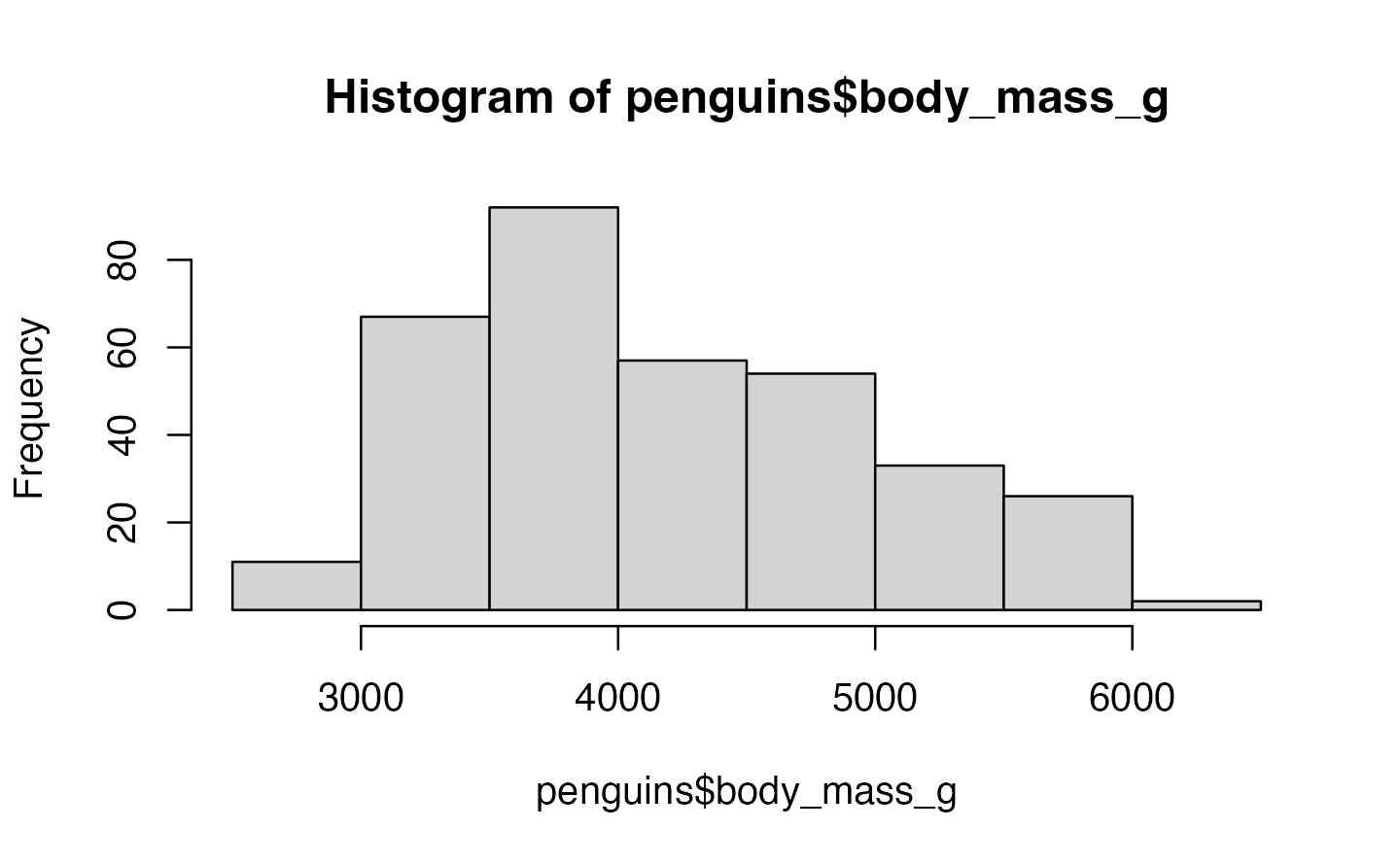
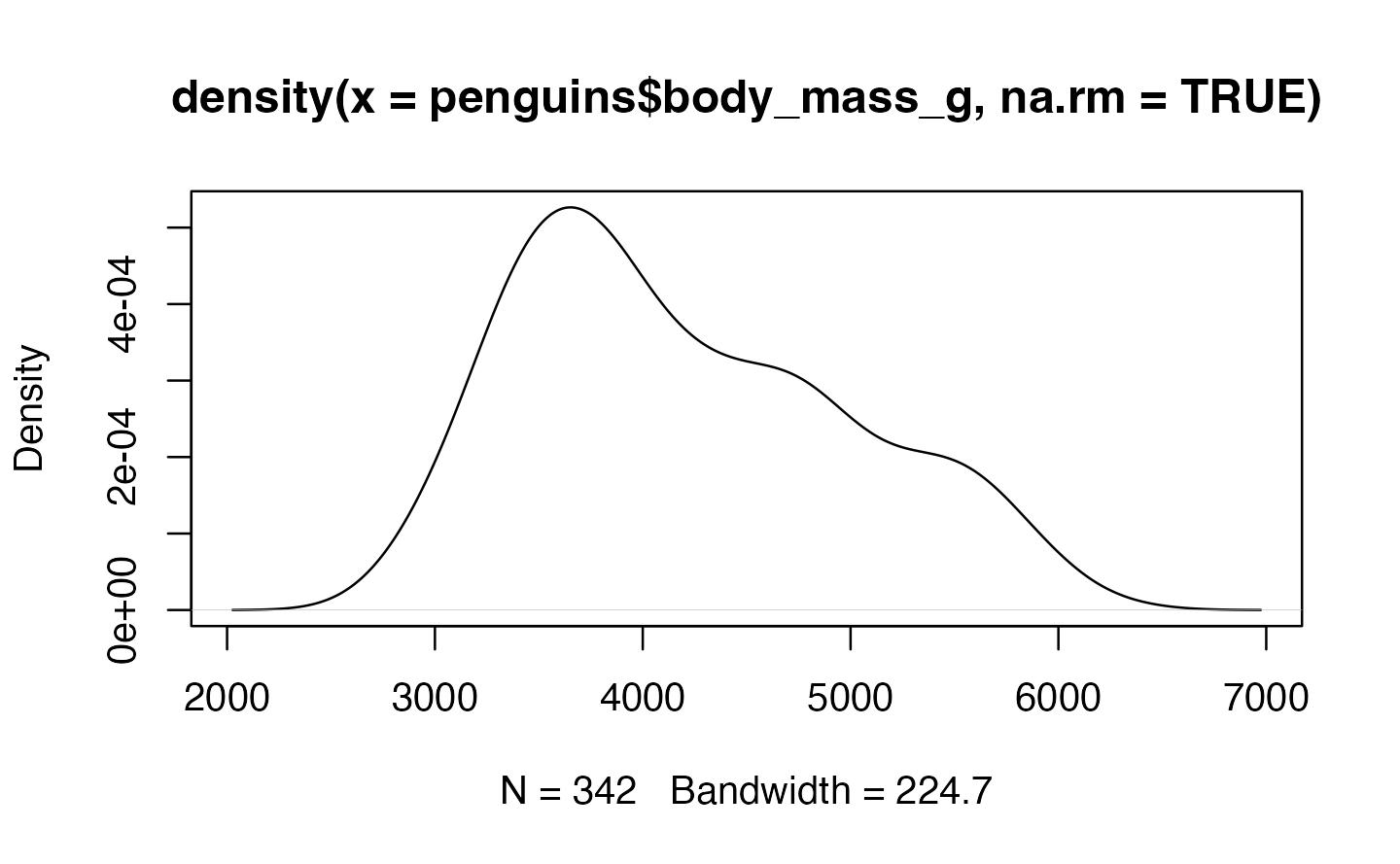
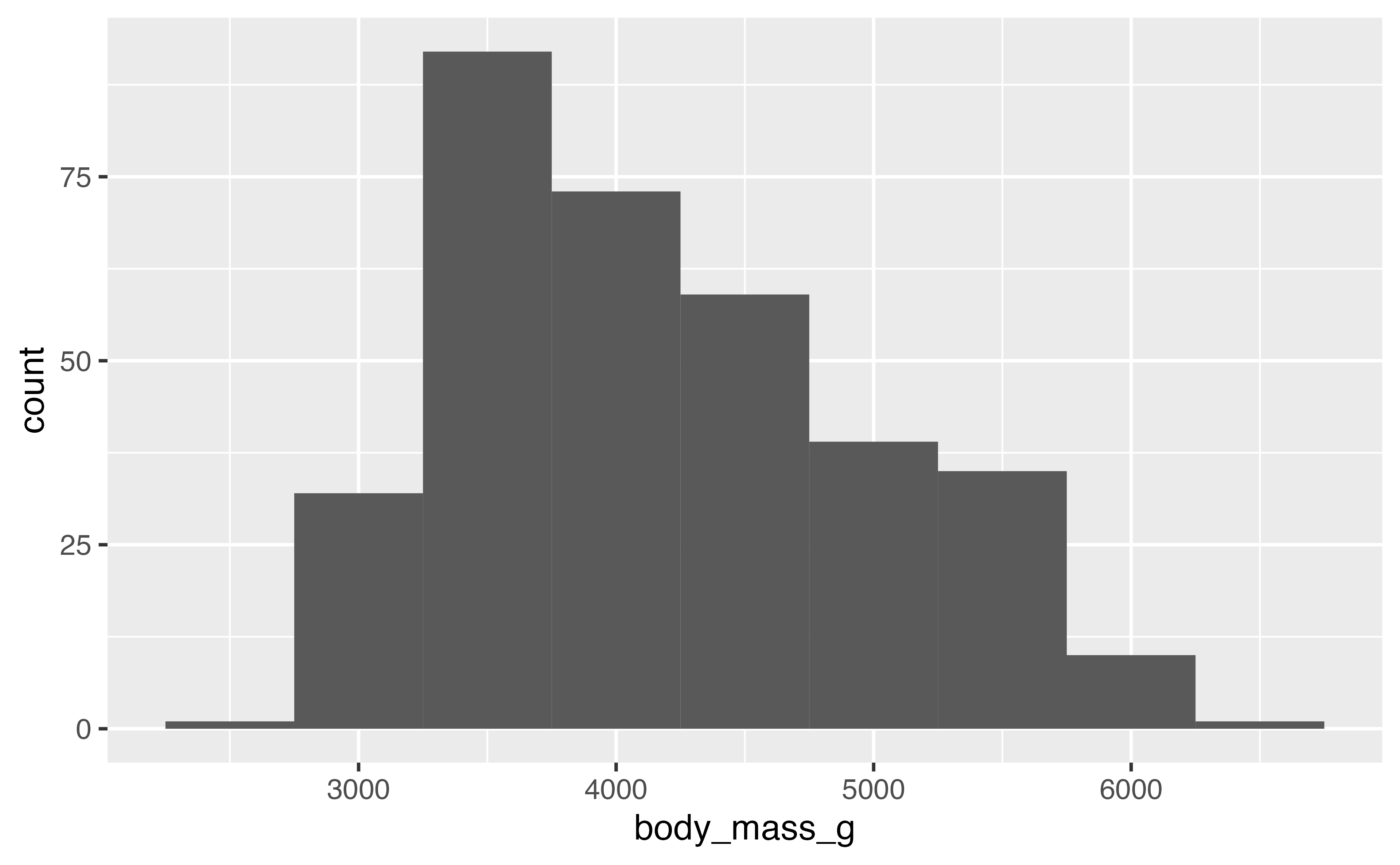
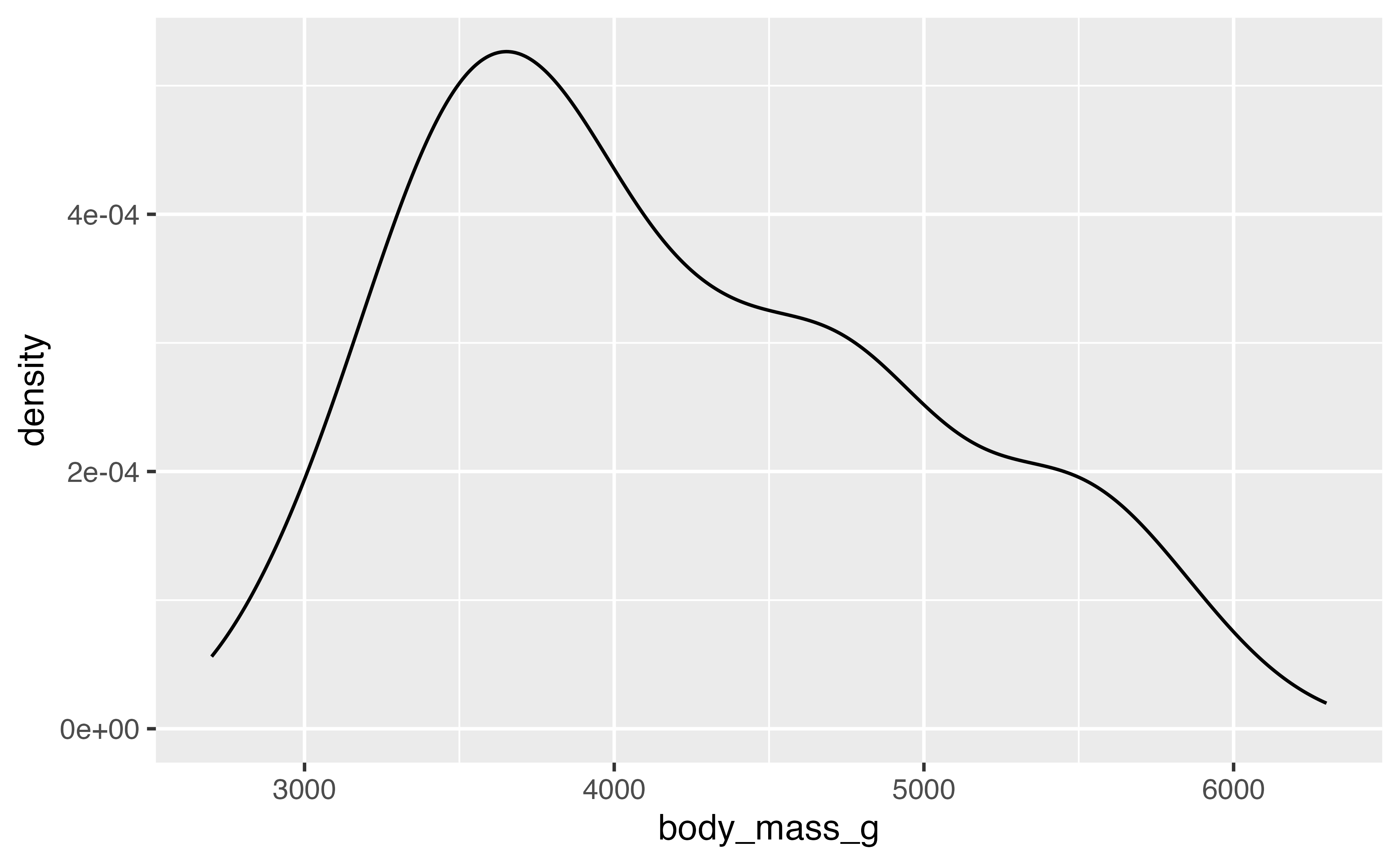
Histogram/Density
Scatterplots
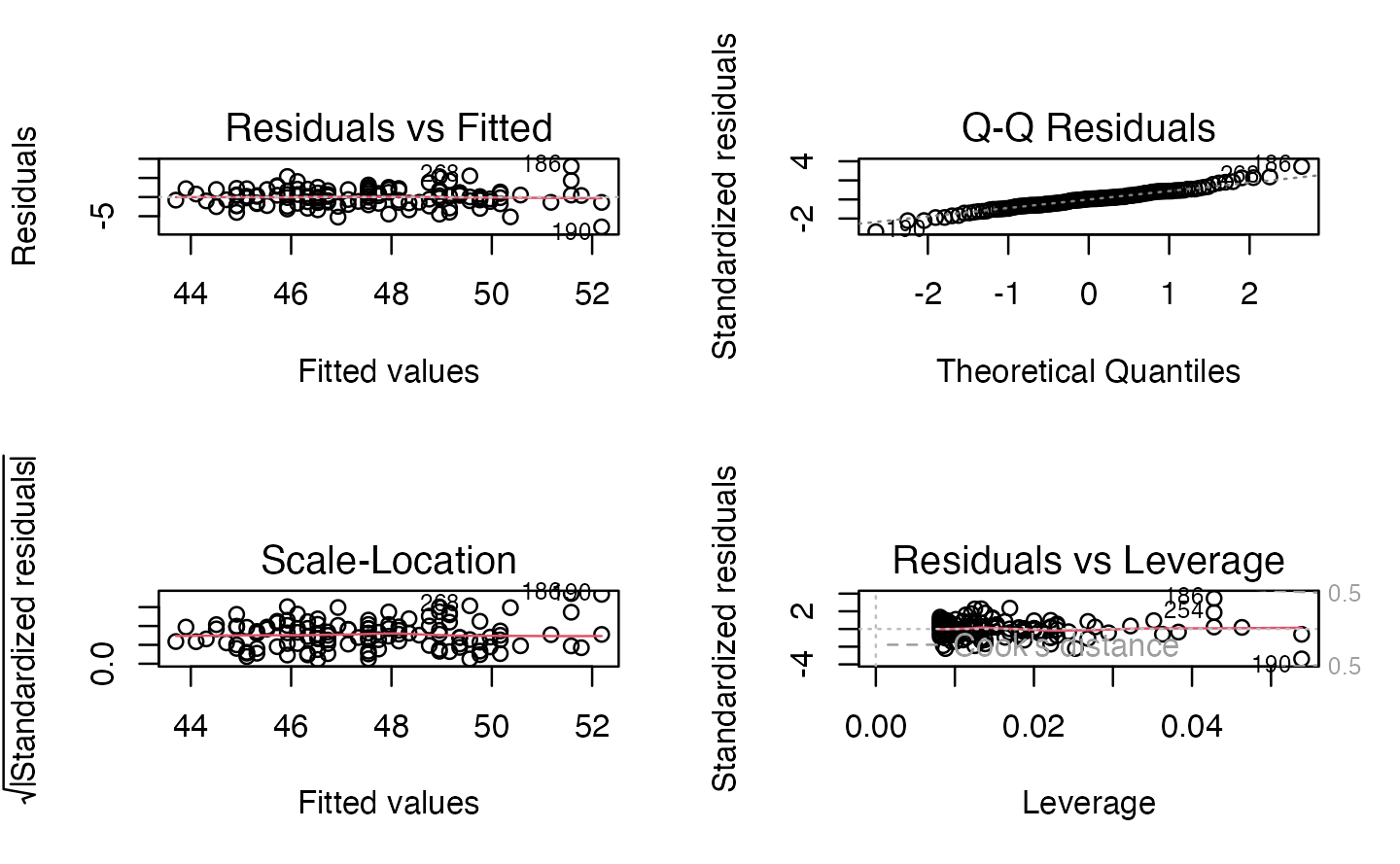
Linear model diagnostic fits
Cake!
Image credit: Tanya Shapiro
Initiate with data
Package is ggplot2 but function is ggplot()

Add aesthetics
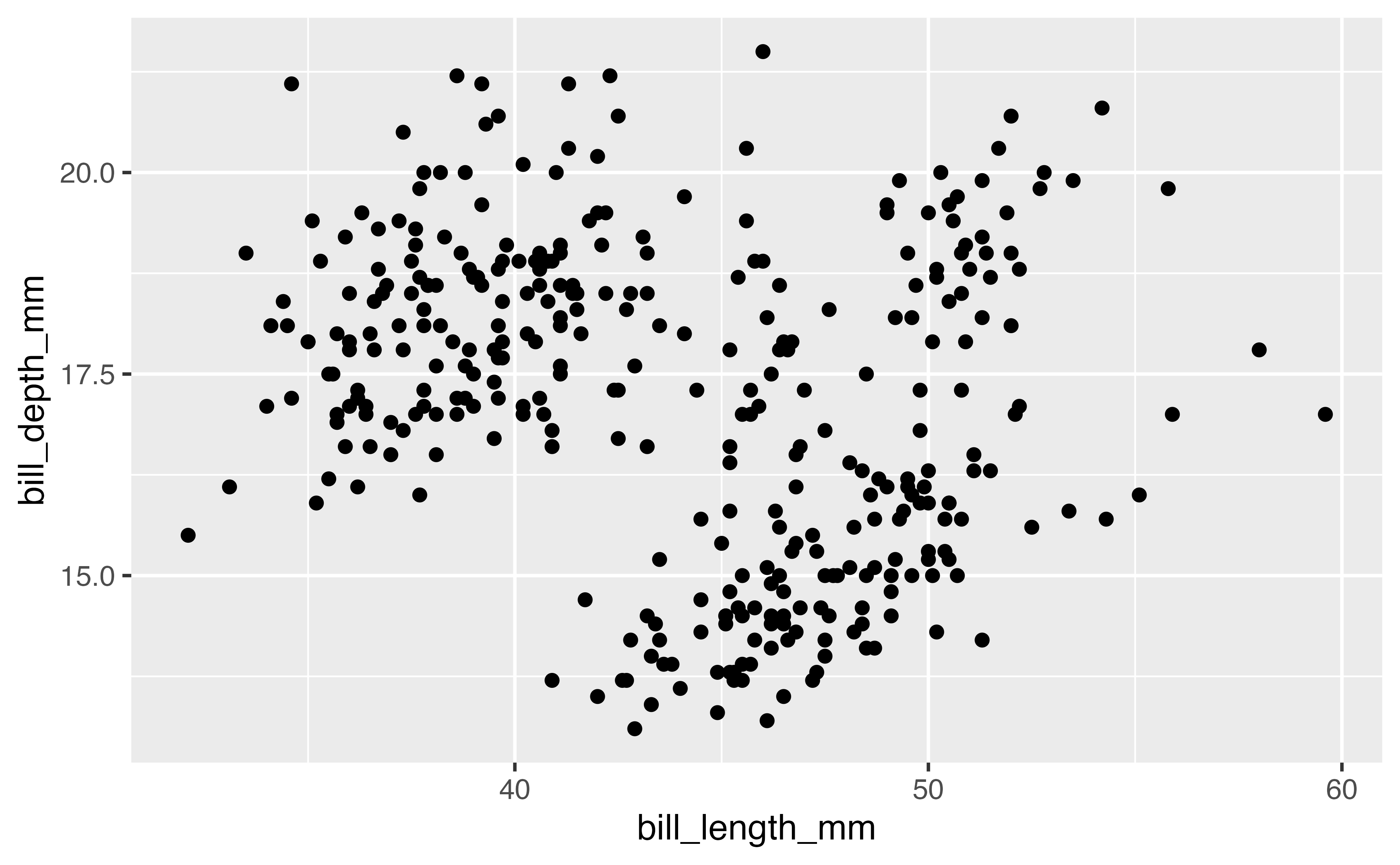
Add points
Layers are added with + (not %>% or |>)
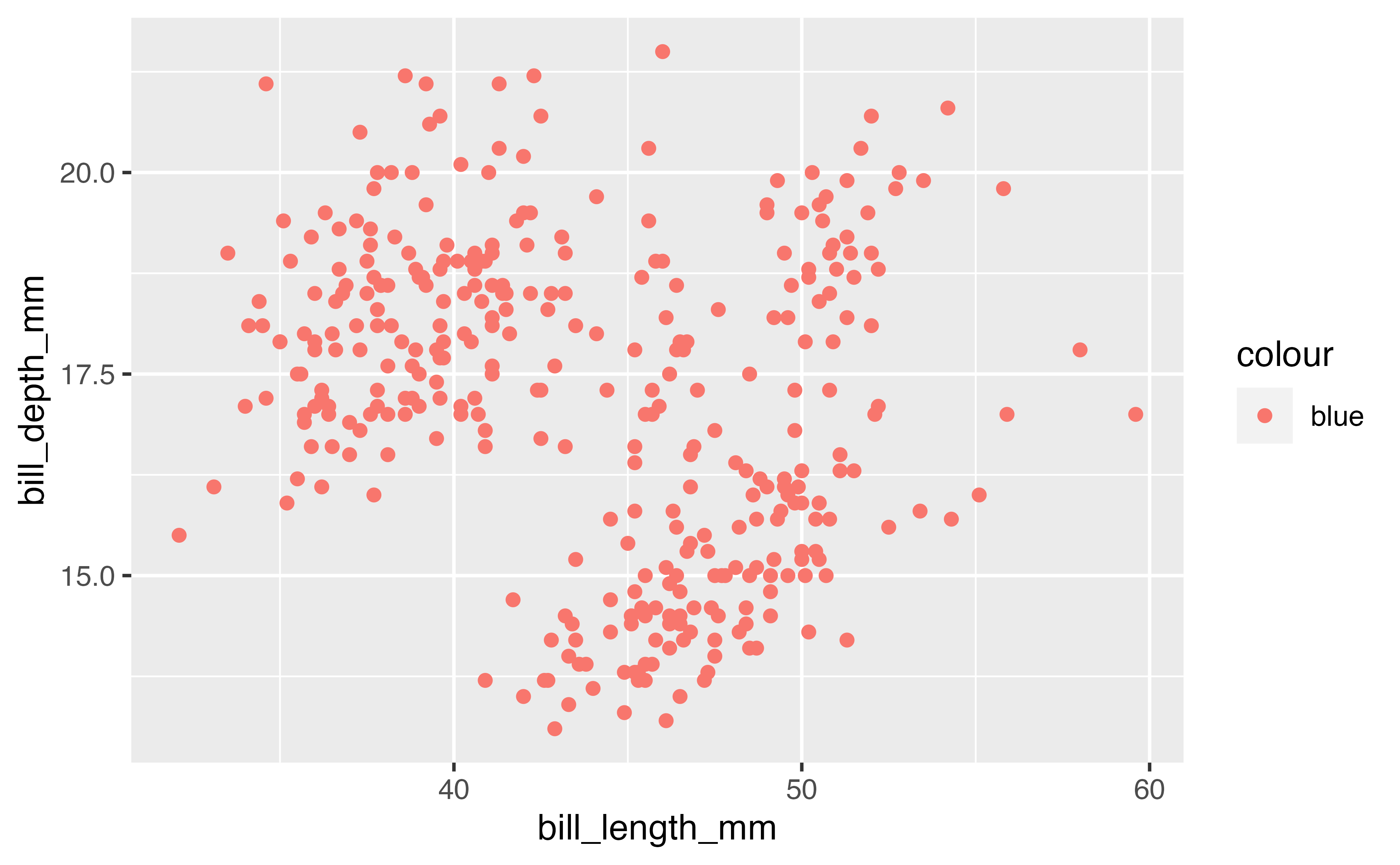
Careful what goes in aes()
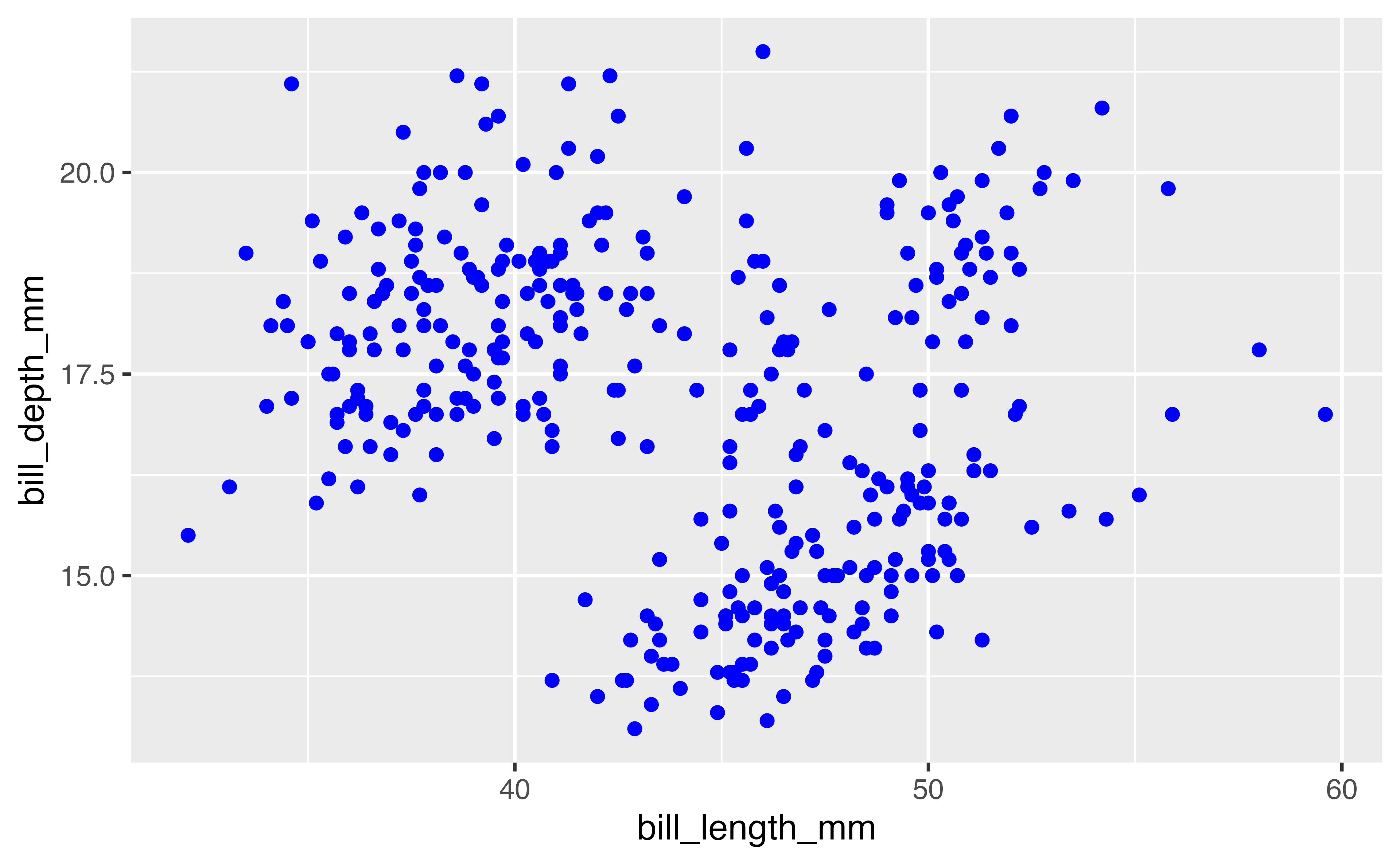
When you do want to map a colour to data
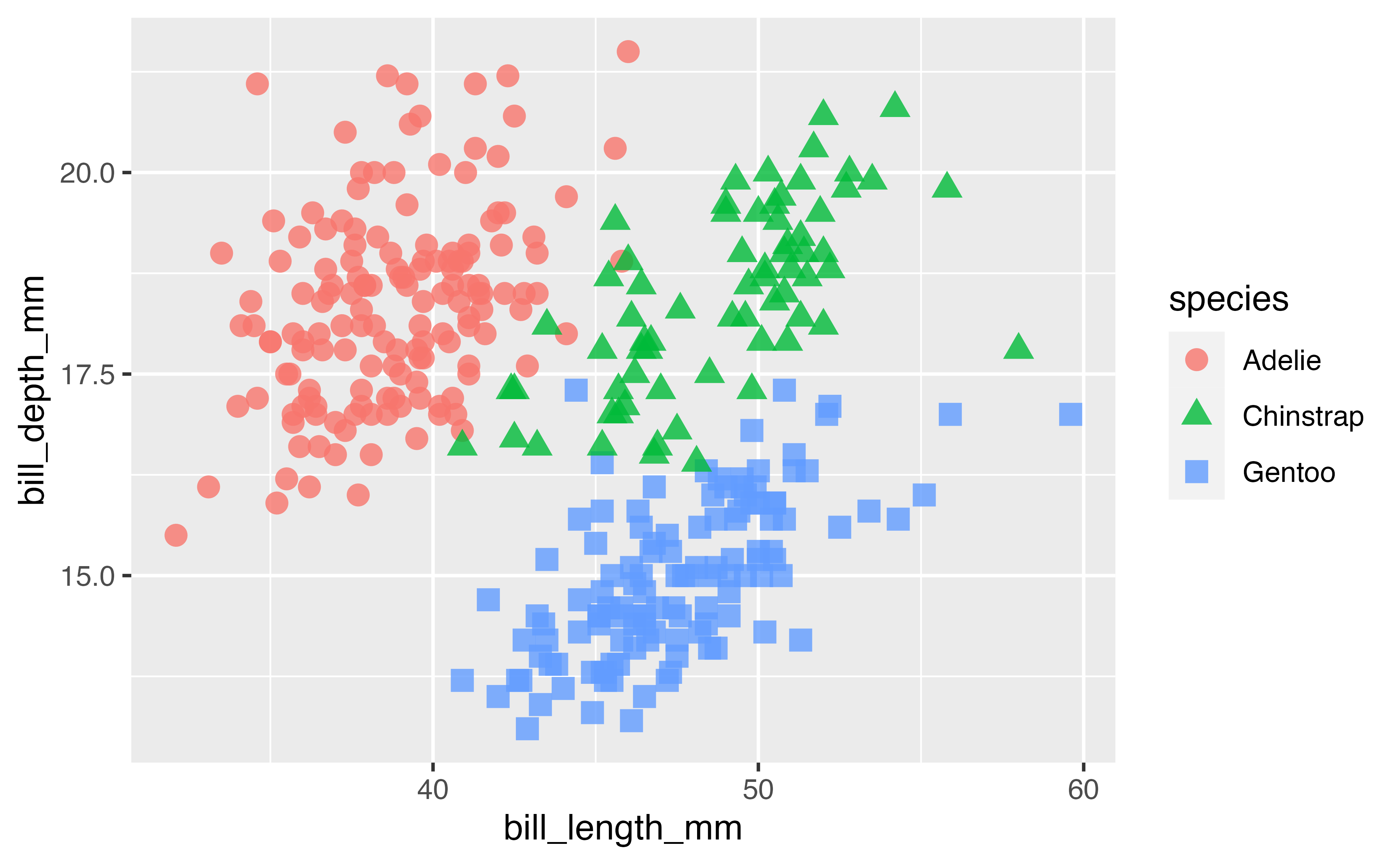
Add additional geoms
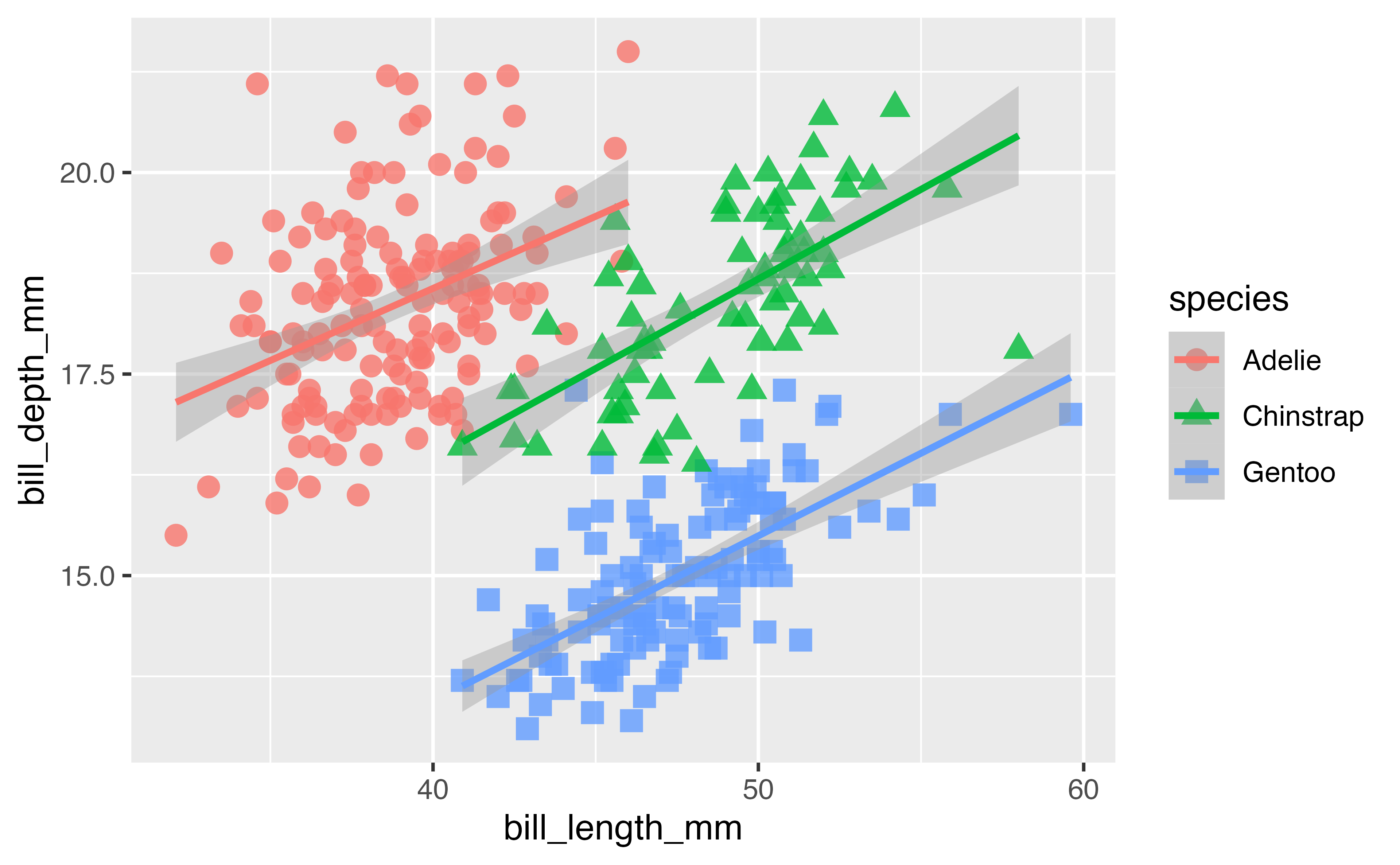
Add a colour scale
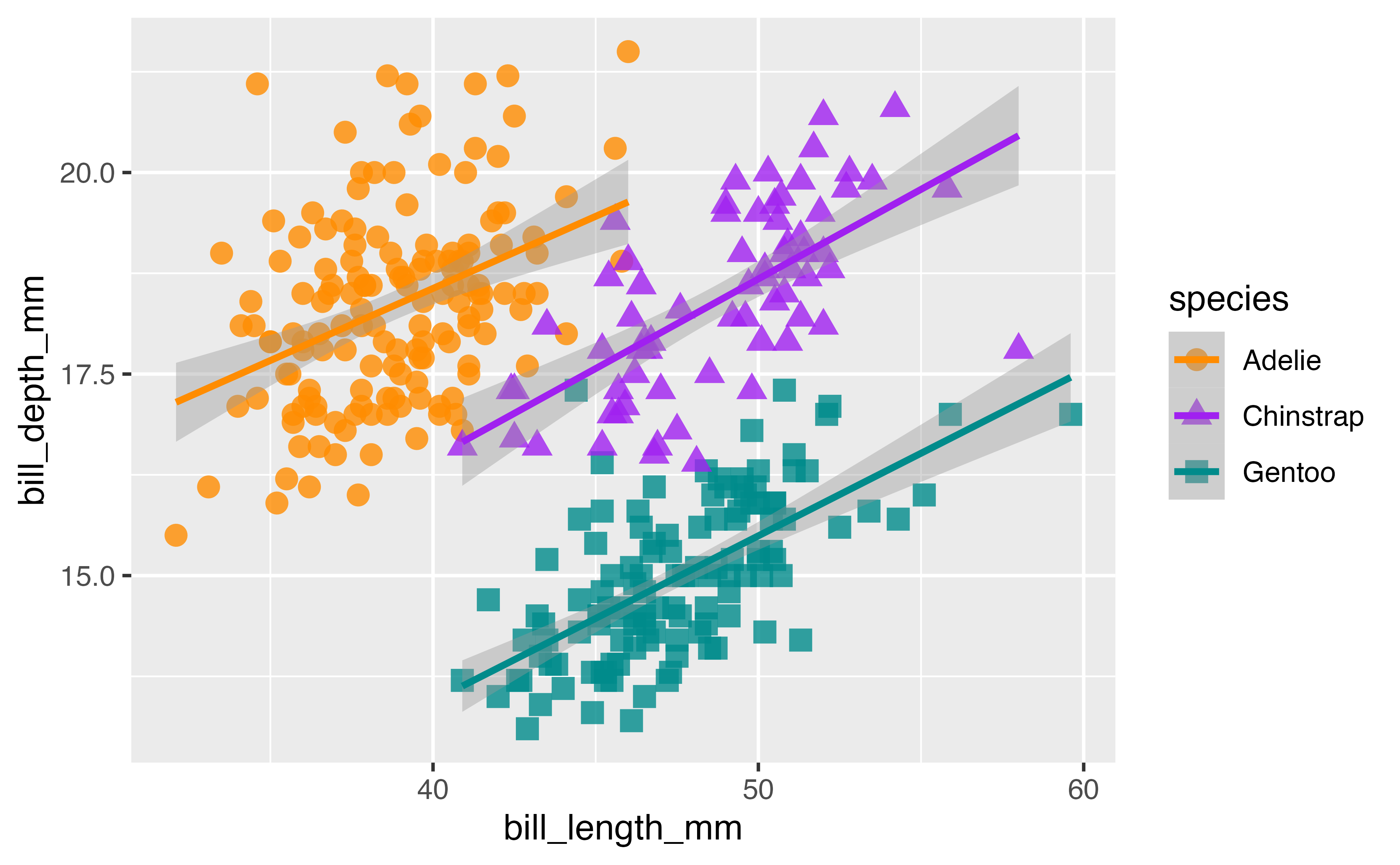
Facets
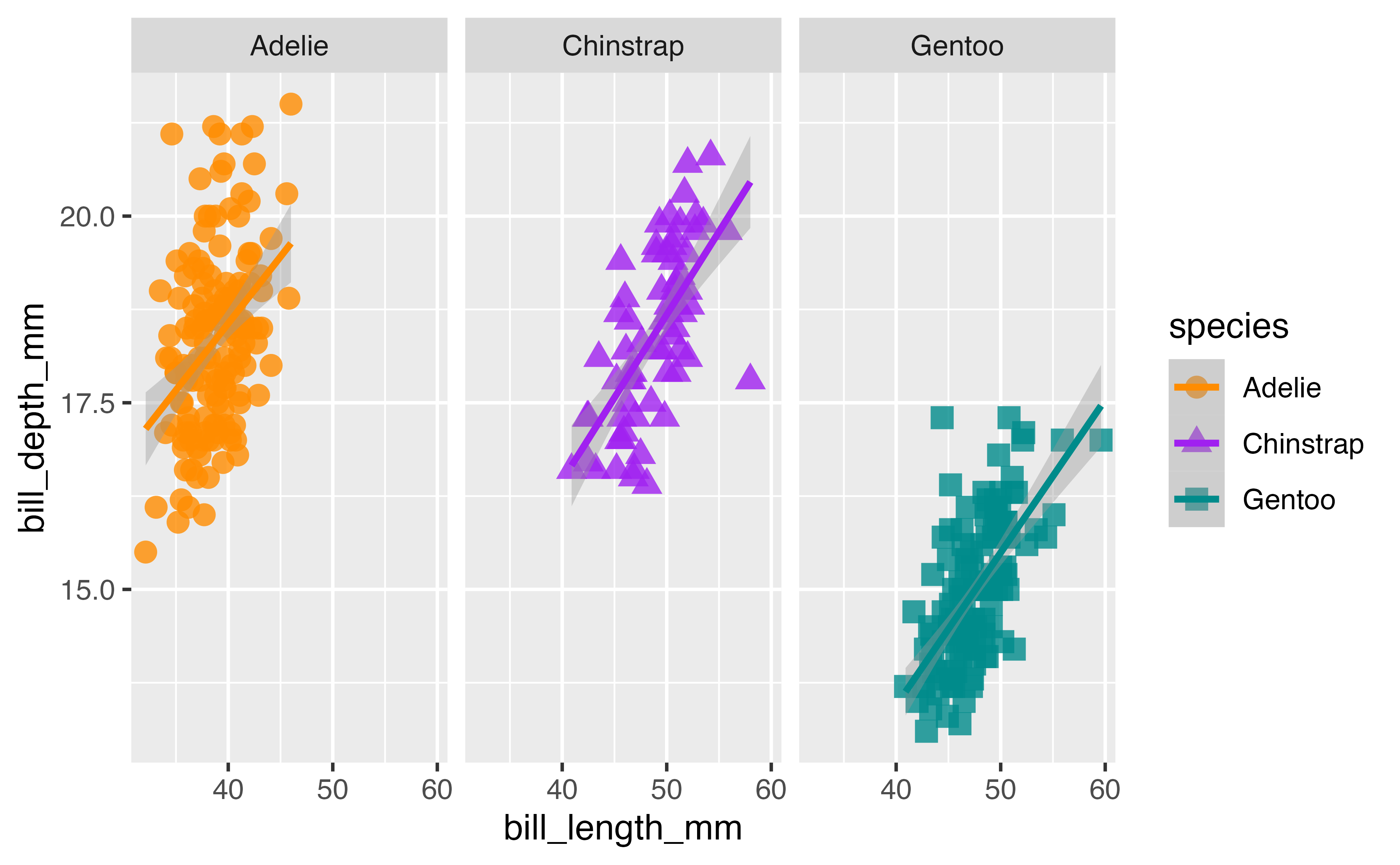
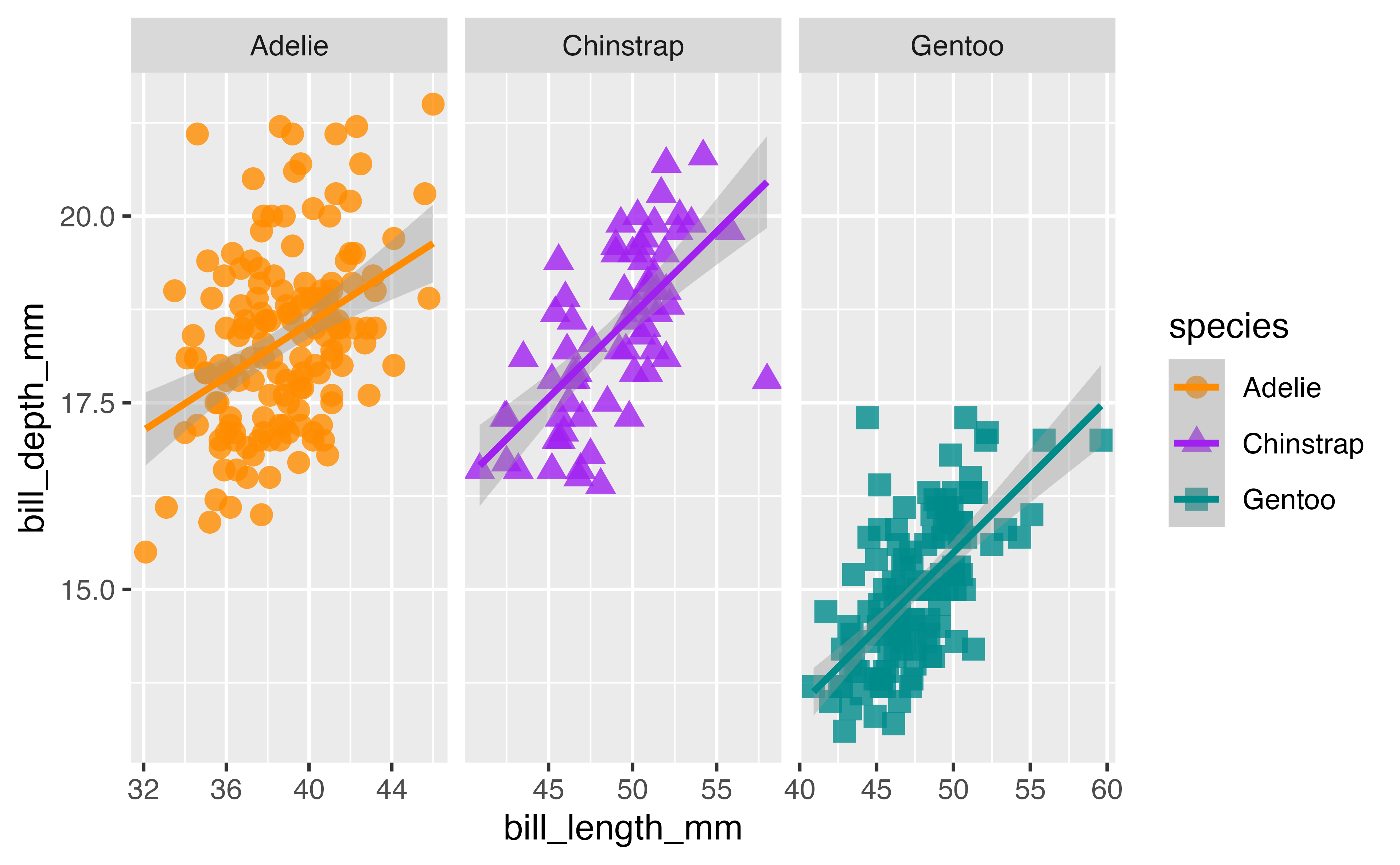
ggplot(data = penguins,
aes(x = bill_length_mm,
y = bill_depth_mm,
group = species)) +
geom_point(aes(color = species,
shape = species),
size = 3,
alpha = 0.8) +
geom_smooth(method = "lm", aes(color = species)) +
scale_color_manual(values = c("darkorange","purple","cyan4")) +
facet_wrap(~species, scales = "free_x")Add theme elements
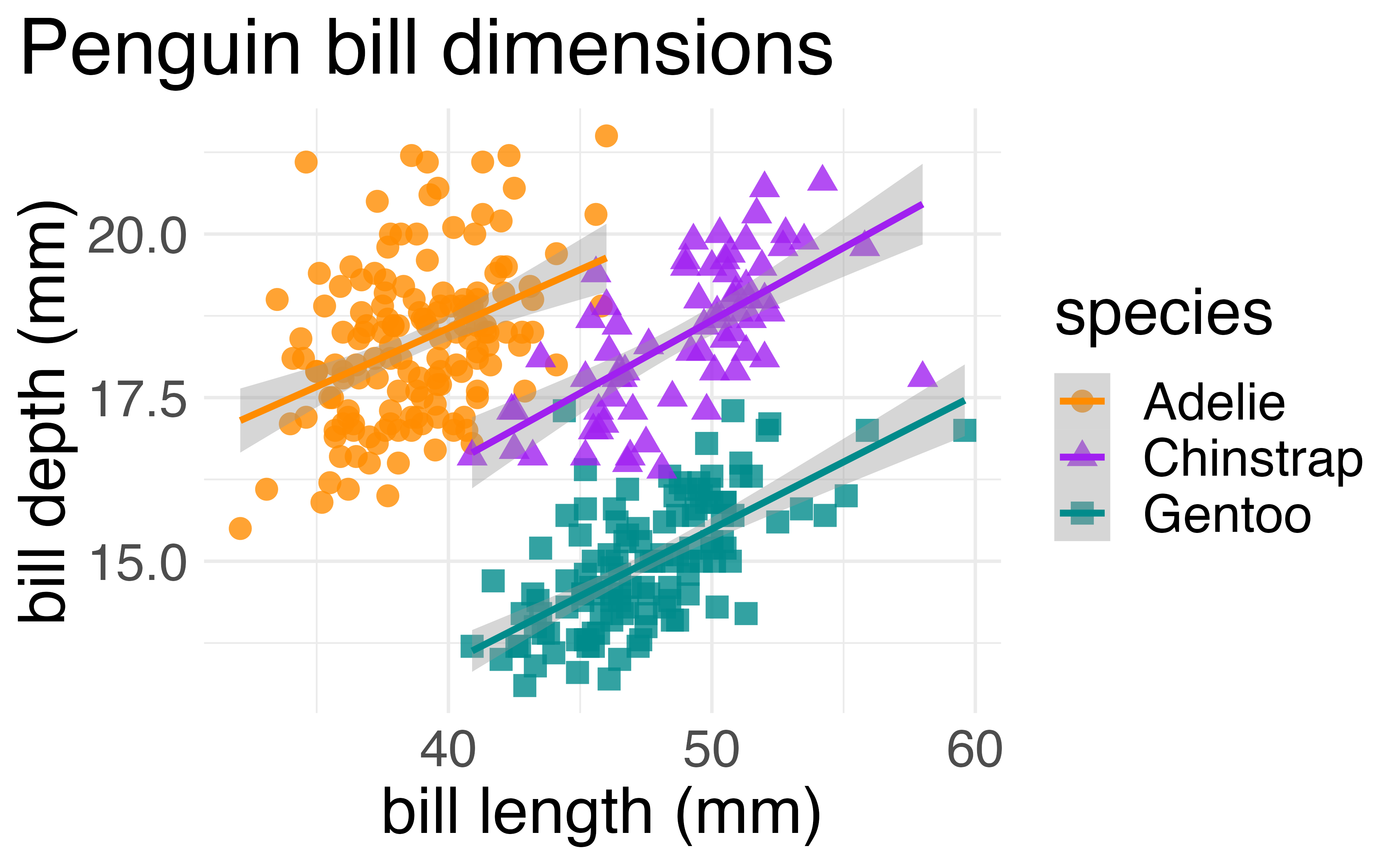
ggplot(data = penguins,
aes(x = bill_length_mm,
y = bill_depth_mm,
group = species)) +
geom_point(aes(color = species,
shape = species),
size = 3,
alpha = 0.8) +
geom_smooth(method = "lm", aes(color = species)) +
scale_color_manual(values = c("darkorange","purple","cyan4")) +
labs(title = "Penguin bill dimensions",
x = "bill length (mm)",
y = "bill depth (mm)") +
theme_minimal() +
theme(plot.title.position = "plot",
text = element_text(size = 20))Boxplot 1
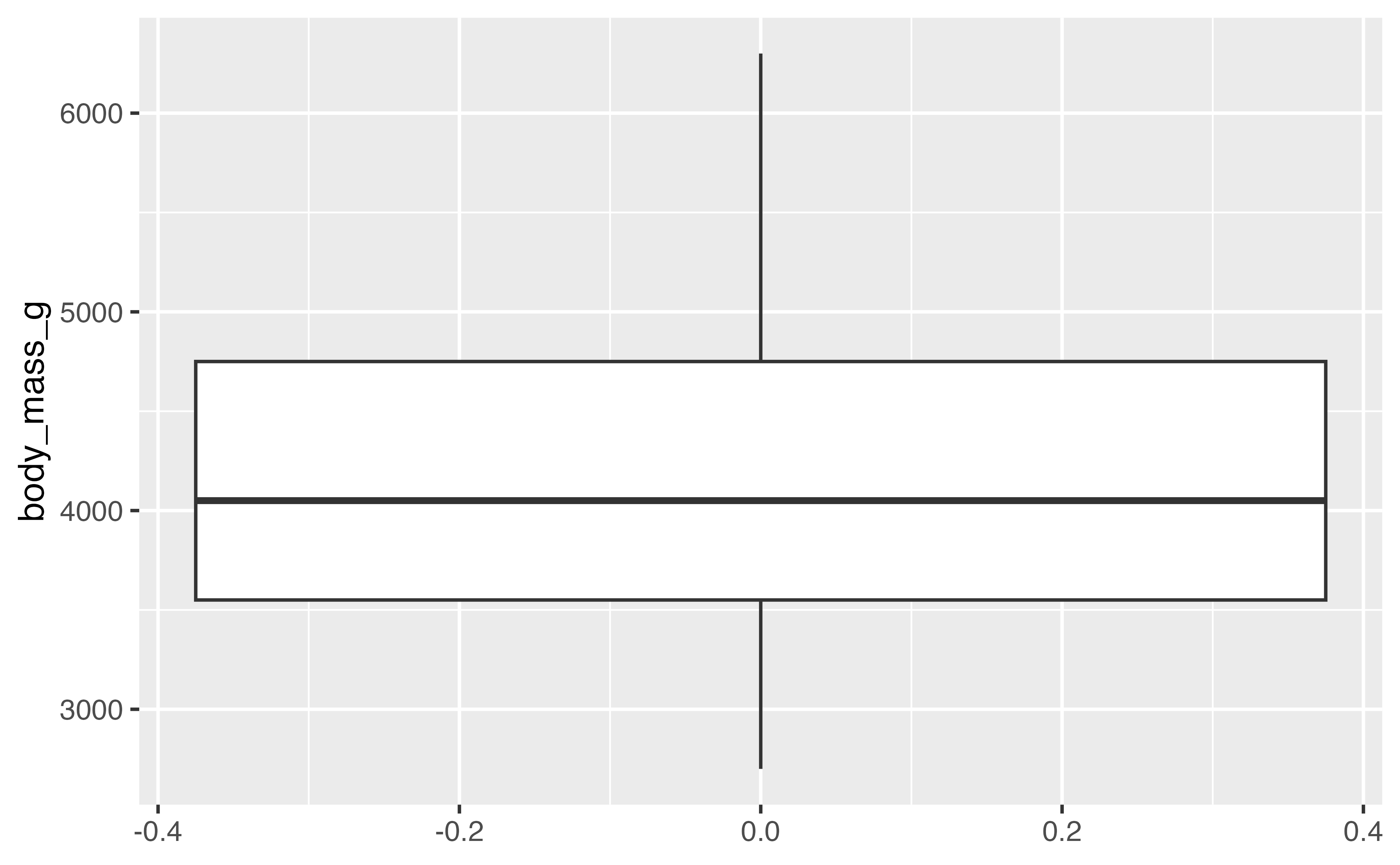
Notes
aes()can be defined for the whole plot or in the geom- first arguments to
aes()arexandy(don’t need to name them if using them in that order)
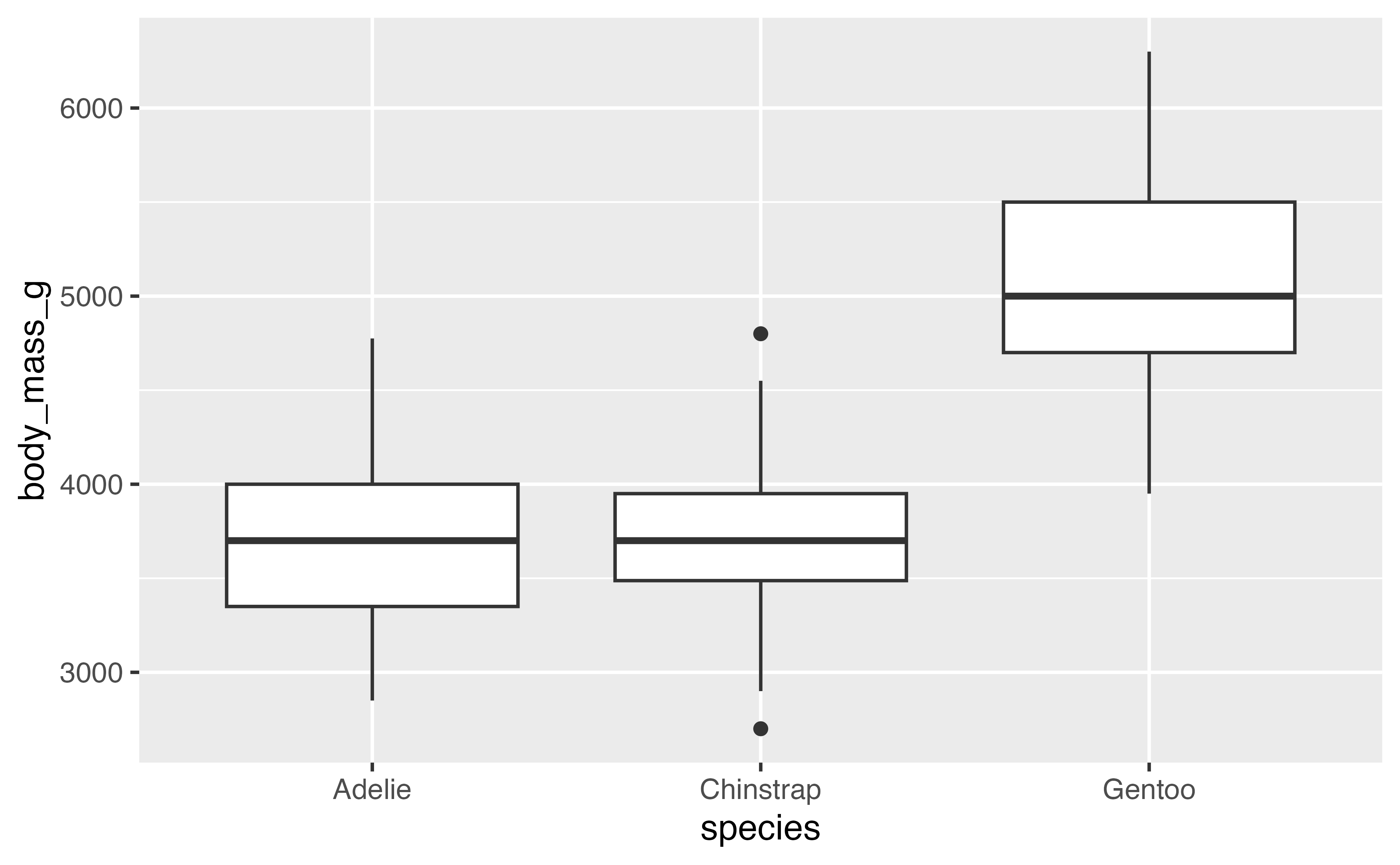
Boxplot 2
Histogram
Density
Scatterplot with vectors
Parts of a gt table

An example
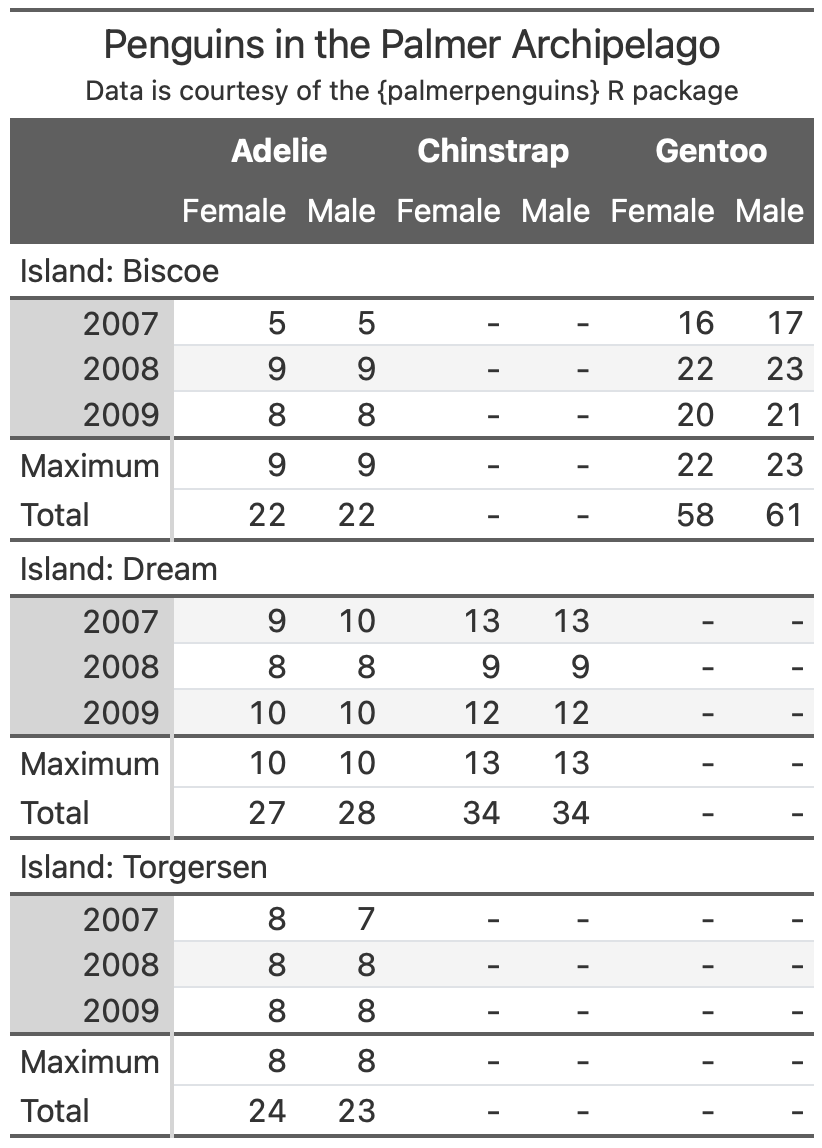
From Albert Rapp’s gt book